
Table of Contents
Introduction: Your Website is Being Crawled by AI Right Now
At this moment, AI systems may be crawling your corporate website.
Not search engines.
AI Agents.
Bots such as GPTBot, ClaudeBot, PerplexityBot, and other emerging generative AI crawlers are actively scanning publicly available content to power training pipelines, retrieval systems, and generative answers across AI interfaces.
For most organizations, this activity is invisible to leadership. It is rarely discussed in boardrooms. It is almost never formally approved. Yet it is already shaping how your content is interpreted, summarized, and surfaced insider AI-driven ecosystems.
For two decades, digital strategy was anchored around discoverability. If Google indexed your content and ranked it well, you succeeded. Visibility equaled traffic. Traffic equaled opportunity.
The AI era disrupts that equation.
AI systems do not simply index. They ingest. The reinterpret. They summarize. They abstract frameworks. They sometimes reproduce reasoning without directing users back to the source.
This shift marks the emergence of a new executive discipline: AI Crawler Governance.
The quesion is no longer:
“Can we rank higher?”
The new question is:
“Should AI systems train on this content, retrieve it, or repackage it?”
For CMOs, CIOs, Chief Digital Officers, and Risk leaders, AI Crawler Governance is not a technical tweak. It is an enterprise control mechanism.
Organizations that treat AI crawler access casually may find their intellectual property diffused across AI systems. Organizations that approach AI Crawler Governance intentionally will shape how their knowledge participates in the AI economy.
What is AI Crawler Governance?
AI Crawler Governance is the structured framework for managing how artificial intelligence agents access, interpret, and utilize your digital content.
It encompasses:
- Technical crawler configuration
- Bpt-specific permissions
- Legal and compliance oversight
- Content classification policies
- Strategic exposure decisions
- Monitoring and enforcement mechanisms
Traditional SEO focused on maximizing visibility. AI Crawler Governance focuses on intentional exposure.
It is the discipline of deciding – not assuming – how AI interacts with your content.
Traditional SEO vs AI Crawler Governance
Traditional SEO asked:
- How do we increase ranking?
- How do we improve click-through rate?
- How do we drive organic growth?
AI Crawler Governance asks:
- Should this content be ingested by AI training systems?
- Does AI summarization dilute competitive advantage?
- Are we formally authorizing AI providerres to use our content?
This sihft is subtle but profound.
SEO optimized for discoverability.
AI Cralwer Governance optimizes for control.
In an environment where AI systems may synthesize your insights into competitors-facing tools, the stakes are materially different.
The Rise of GPTBot, ClaudeBot and Autonomous AI Agents
The ecosystem of AI crawlers is expanding rapidly.
Industry data shows that AI crawlers now account for about 4.2% of all HTML requests globally, with major players like GPTBot representing a growing share of that traffic – signaling that AI access is significant and rising. (Source: seomator.com)
OpenAI’s GPTBot, Anthropic’s ClaudeBot, and other AI agents operate with varying declared purposes – including model training, content indexing, and retrieval-based answering.
Beyond headline proividers, industry-specific AI systems are emerging in finance, healthcare, legal services, and enterprise software. Many of these tools rely on automated content ingestion.
The results: a multi-layered AI crawling environment that evolves faster than traditional search engine behavior.
AI Crawler Governance must therefore be adaptive, not static.
Why robots.txt Alone Is No Longer Enough
For years, robot.txt was sufficient for controlling indexing behavior.
In the AI era, the landscape is more nuanced:
- Some AI bots respect robot.txt
- Some differentiate between training and retrieval
- Some operate through partnerships
- Some rely on third-party aggregators
Blanket blocking may reduce brand visibility in AI interfaces. Blanket allowing may expose proprietary intellectal property.
AI Crawler Governance requires strategic segmentation, not bineary decisions.
The Economic Shift: How AI Crawlers Refine Content Value
Digital content used to create predictable value chains:
Content -> Ranking -> Traffic -> Conversion.
AI systems introduce a parallel chain:
Content -> Ingestion _> Synthesis -> AI Answer -> Reduced Traffic.
This is not inherently negative. But it changes the economic calculus.
AI Crawler Governance becomes necessary because AI-mediated visibility does not always return direct traffic value.
AI Summaries and the Changing Click Economy
AI-powered search summaries are already reshaping user behavior: top-ranking pages experience a reduction in click-through rate (CTR) of up to 34.5% when AI overviews appear in search results – and zero-click behavior has become increasingly common. (Source: rebootonline.com)
Many organizations are observing increased impressions alongside declining click-through rates as AI-generated answers appear in search interfaces and AI assistants.
According to recent research, AI-powered answers now account for roughly 40% of online searches, with 80% of consumers using AI summaries for information discovery – fundamentally altering how users interact with search results. (Source: nav43.com)
If AI systems summarize your thought leadership directly within a chat interface, users may never visit your website.
In some cases, that visibility strengthens brand recall.
In others, it commoditizes expertise.
AI Crawler Governance requires organizations to evaluate where AI exposure enhances brand equality versus where it erodes commercial leverge.
Competitive Intelligence Risks
Consider content categories such as:
- Pricing frameworks
- Risk assessment methodologies
- Marketing operating models
- Customer segmentation logic
- Conversion optimization strategies
When AI systems ingest such materials deeply, they may abstract structural insights that competitors can indirectly access through AI interfaces.
This does not imply malicious behavior. It reflects the nature of generative AI systems.
AI Crawler Governance introduces strategic differentiation:
Not all content should be equally visible to AI.
Intellectual Property and Derivative Logic
One of the most under-discussed aspects of AI Cralwer Governance is derivative abstraction.
Even if AI systems do not reproduce text verbatim, they may internalize reasoning patterns and structural frameworks.
Organizations that publish proprietary methodologies publicly must now consider:
- Is this framework core competitive IP?
- Does AI ingestion reduce differentiation?
- Should certain materials be partially gated?
These are board-level considerations.
The C.A.V.E™ Framework: Structured Controlled AI Visibility
To operationalize AI Crawler Governance, organizations requires a structured model.
The C.A.V.E ™ framework provides that structure:
- Control
- Authorize
- Value
- Enforce
It reframes AI exposure as an enterprise governance system rather than a technical adjustment.
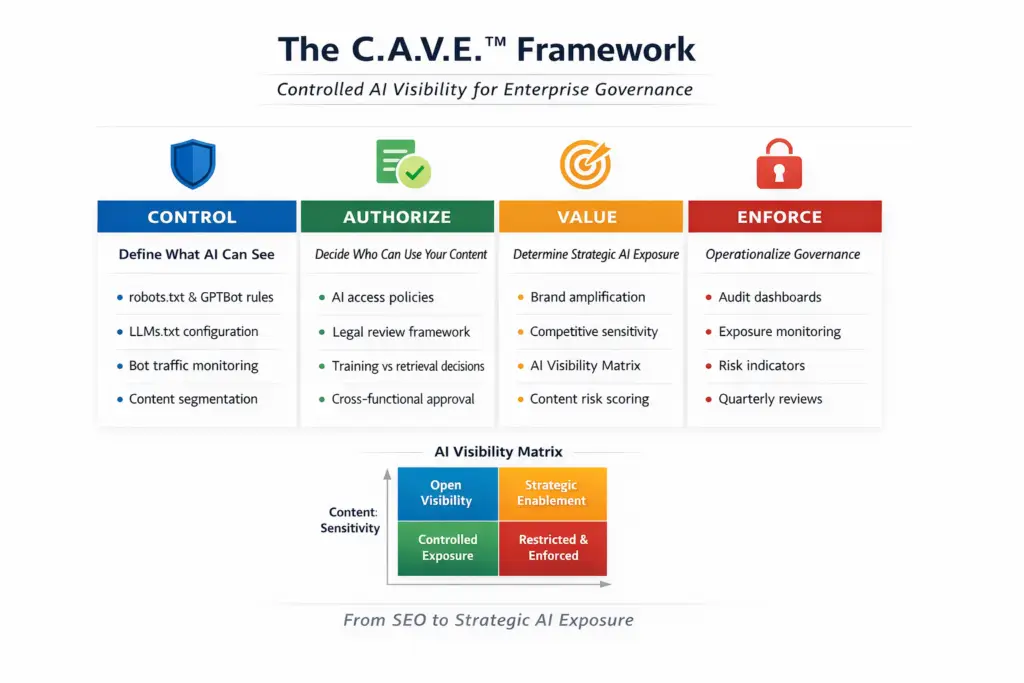
Pillar 1: CONTROL – Define What AI Can See
Control is the technical foundatin of AI Crawler Governance.
This includes:
- Robit.txt configuration for AI bots
- Bot-specific directives (GPTBot, ClaudeBot)
- IP-based filtering
- Rate limiting
- Log-based cralwer analytics
- Emerging LLMs.txt standards
However, control should not default to restriction.
An effective AI Crawler Governance strategy classifies content into tiers:
- Public marketing content
- Educational though leardreship
- Proprietary frameworks
- Commercially sensitive data
- Internal documentation
Each tier warrants differentiated AI visibility settings.
Control establishes boundaries – but strategy requires authorization.
Pillar 2: AUTHORIZE – Formalize AI Access Decisions
Many organizations allow AI bots by default simply because no policy exists.
Authorization formalizes decisions regarding:
- Which AI providers are permitted access
- Whether model training ingestion is allowed
- Whether retrieval-only access is acceptable
- Whether contractual relationships influence access
AI Cralwer Governance become credible when leadership explicitly approves or restricts AI exposure categories.
This is particularly critical in regulated sectors, where content interpretation has compliance implications.
Authorization aligns AI access with enterprise risk appetite.
Pillar 3: VALUE – Evaluate Strategic AI Exposure
Not all AI visibility is undesirable.
Selective AI presence may strengthen:
- Brand authority
- Thought leadership positioning
- Citation frequency in AI answers
- Market perception of expertise
AI Crawler Governance requires organizations to define where AI exposure generates strategic upside.
The AI Visibility Matrix
Two axes guide decision-making:
- Content Sensitivity (Low to High)
- AI Strategic Value (Low to High)
This produces four quadrants:
- Open Visibility – Encourage AI indexing for brand-building content.
- Strategic Enablement – ALlow monitored exposure where value exceeds risk.
- Controlled Exposure – Limited access to selected AI agnts.
- Restricted & Enforced – Block or tightly manage highly sensitive content.
This matrix transforms AI Crawler Governance from reactive blocking into strategic calibration.
Pillar 4: ENFORCE – Monitor and Institutionalize Governance
Policy without enforcement creates exposure drift.
Enforcement mechan isms include:
- AI crawler traffic dashboards
- Automated anomaly detection
- Quarterly AI visibility audit
- Version-controlled cralwer configurations
- Cross-functional governance reviews
Organizations may also implement an AI Visibility Risk Indicator scoring model, evaluating:
- Competitive sensitivity
- Regulatory exposure
- Revenue dependency
- Replicability risk
- Strategic AI amplification ptential
AI Crawler Governance must become continuous rather than episodic.
Technical Foundations: Implementation Without Over-Engineering
While executive strategy is critical, execution remains practical.
robot.txt Best Practices for AI Bots
- Use bot-specific rules
- Avoid blanket disallow policies
- Separate AI bot logic from search engine logic
- Maintain documented change logs
AI Crawler Governance should treate robot.txt as a dynamic governance artifact rather than static configuration.
GPTBot and ClaudeBot Configuration Considerations
Organizations must evaluate:
- Full allow
- Partial allow
- Full disallow
Decisions should align with C.A.V.E.™ content classification tiers.
Consistency is essential. Random experimentation undermines governance integrity.
LLMs.txt: Emerging Communication Layer
LLMs.txt has been proposed as a mechanism to communicate AI-specific crawling preferences.
Adoption remains uneven. However, it signals a future wher AI Crawler Governance becomes more standardized.
Forward-looking enterprises should monitor development closely.
Legal and Regulatory Dimensions of AI Crawler Governance
AI Crawler Governance intersects with law in several ways.
Copyright and Licencing
Public content does not automatically equate to unrestricted AI usage.
Organizations must evaluate:
- Terms of service clarity
- Jurisdictional copyright protections
- Enforcement feasibility
Legal teams should collaborate with digital terms to align policy.
Training vs Retrieval Distinction
Some AI systems differentiate between:
- Long-term training data ingestion
- Real-time retrieval from indexed sources
AI Crawler Governance policies should recognize this distinction and reflect organizational risk appetite.
Financial Services and Regulated Industries
For banks, fintechs, and regulated enterprises:
- Regulatory disclosures must remain accurate
- AI reinterpretation could alter nuance.
- Data localization laws may complicate training exposure
AI Crawler Governance in regulated industries cannot be delegated solely to IT.
Building an Enterprise AI Bot Governance Policy
Institutionalizing AI Crawler Governance requires structure.
Governance Ownership
- Executive sponsor (CDO, CIO, or equivalent)
- Cross-functional steering group
- Legal and compliance advisory representation
Policy Framework Components
- Content classification matrix
- Bot permission registry
- Escalation process
- Review cadence
- Documentation standards
Performance Metrics
- AI bot traffic ratio
- Content exposure distribution
- Policy deviation alerts
- Risk score trend analysis
AI Crawler Governance should appear in digital risk reporting alongside cybersecurity and data governance.
Governance Maturity Model for AI Crawler Governance
Organizations typically evolve through stages:
- Unaware – No AI bot monitoring
- Reactive – Ad-hoc monitoring
- Defined – Documented crawler policies
- Managed – Structured enforcement and audits
- Strategic – AI exposure aligned with competitive positioning
Mature AI Crawler Governance integrates marketing, technology, legal, and risk into a coherent operating model.
The 2026 – 2028 Outlook: From Visibility to Digital Sovereignity
AI agents will multiply.
Autonomous AI-to-AI interactions may emerge, negotiating data access dynamically.
In such an environment, passive visibility becomes untenable.
Organizations must move toward digital sovereignty – defining how corporate knowlege participates in AI ecosystems.
AI Crawler Governance becomes foundational to that sovereignty.
It is not a temporary defensive measure. It is a long-term competitive architecture.
Conclusion: Visibility Is Now Strategic Exposure
The era of maximizing exposure without qualification is ending.
AI Crawler Governance reframes digital visibility as calibrated exposure.
SEO was about discoverability.
AI Crawler Governance is about control.
The organizations that win in the AI era will not be the most visible everywhere.
They will be the most strategically exposed – intentionally, selectively, and governed with precision.
Read my other articles on AI Search Optimization here.








