
Table of Contents
Introduction: Why AI Marketing Ambitions Often Outrun Data Reality
Artificial intelligence has moved from experiementation to expectation. Marketing teams are now expected to personalize journeys, predict intent, optimize campaigns, improve content relevance, and support faster decisions. In many organizations, the conversation has shifted from whether AI matters to how quickly it can be deployed.
Yet this urgency has exposed a deeper problem. Many AI initiatives are being layered onto data environments that were never designed for them. Customer records remain fragmented across platforms. Behavioral signals arrive too slowly. Consent data is inconsistent. Identity cannot be reliably connected across channels. Teams debate whether they need a CDP, a warehouse, or another point solution, but the underlying issue is often larger than platform selection.
That issue is data readiness.
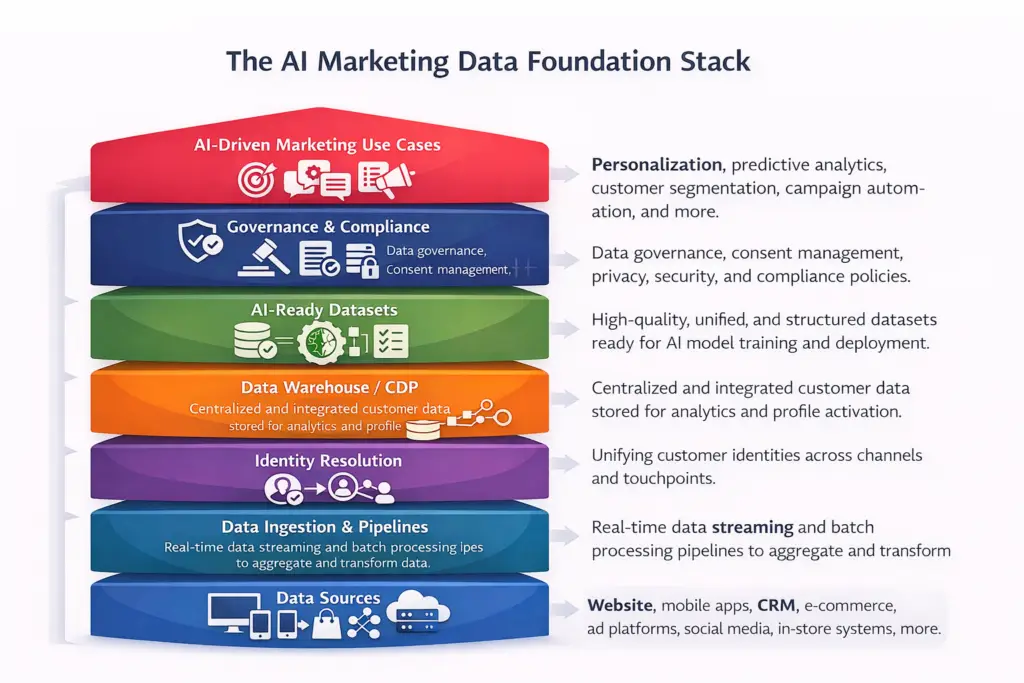
This is where AI marketing data infrastructure becomes strategically important. It is not simply a technical topic for data teams. It is the business foundation that determines whether AI can produce relevance, speed, trust, and measurable value. Without a strong foundation, AI may still generate outputs, but those outputs are often incomplete, mistimed, or difficult to scale.
The commercial stakes are real. McKinsey notes that personalization can reduce customer acquisition cost by as much as 50 percent, lift revenue by 5 to 15 percent, and improve marketing ROI by 10 to 30 percent. That is precisely why weak data foundations matter so much: they limit the organization’s ability to capture value from AI-powered personalization and decisioning. (Source: Mckinsey)
This article explores what that foundation must look like. It explains why data readiness now matters more than ever, how to think about CDPs vs data warehouses, why indentity resolution and real-time pipelines are critical, what makes a dataset AI-ready, and why governance and compliance must be part of the architecture from the start. The central message is simple: without strong data foundations, AI marketing initiatives stall.
Why Data Foundations Matter More Than Ever in AI-Driven Marketing
AI is only as strong as the data that fees it
One of the most persistent misconceptions in the market is that AI can compensate for weak data. In reality, it often does the opposite. AI magnifies the strengths and weaknesses of the underlying data environment.
If customer data is incimplete, the AI output will be incomplete. If event catpture is inconsistent, recommendations will be inconsistent. If product information is poorly structured, AI-generated suggestions or content may become less relevant. If identity cannot be resolved across channels, the customer experience becomes fragmented.
cause marketing outcomes are shaped by context. A recommendation engine needs to understand past behavior, current intent, and product relationships. A next-best action model nees access to recent signals and reliable profile information. A retention model depends on historical consistency. A personalization layer must know enough about the customer to adapt intelligently.
All of these depend on data quality before they deoend on algorithm sophistication.
That is not merely a technical issue. Gartner says poor data quality costs orgtanizations at least $12.9 million per year on average. In an AI-driven environment, that cost is not just operational waste. It becomes a growth constraint because poor data quality weakens targeting, relevance, attribution, and trust. (Source: Gartner)
Modern marketing use cases need connected, usable, and timely data
AI in marketing is not one use cased. It is a collection of use cases, each with its own data requirements.
Audience intelligence needs reliable behavioral and transactional history. Journey orchestration depens on recent events and channel responsiveness. Predictive models require structured historical data. Generative AI copilots needc access to approved content, customer context, and enterprise knowlege. Dynamic offer decisions depend on timing, eligibility, and customer state.
These use cases raise the bar for data maturity. In older marketing environments, data could be siloed and still remain somewhat useful. A CRM platform could power email. Web analytics could support reporting. Paid media data could stay largely separate. AI makes these silos more costly because decision quality depends on how well signals can be connected.
This is why AI marketing data infrastructure should be treated as a capability rather than a back-end utility. It ensures that data is not only stored, but also structured, joined, interpreted, and activated in ways that support intelligent marketing.
The hidden reason many AI projects stall
Many AI programs do not fail because teams lack ambition. They stall because the operational conditions for success are missing.
Often the symptoms are subtle. A model performs well in a test but is difficult to deploy. A personalization use case launches but fell generic. A new AI tool is purchased but sits underused because the right data cannot be integrated. Marketing, data, and compliance teams disagree on how customer information can be used. Metrics do not line up across platforms, so trust in the output declines.
The challenge is widespread. Salesforce’s latest marketing research notes that unifying customer data from disparate sources remians a major technical hurdle, and a related Salesforce session summarizing the same report says only 25% of marketers are satisfied with their customer data unification. Salesforce also reports that high-performing marketers are 2.4 times more likely to have unified their data sources. (Source: Salesforce)
These are not side issues. They are signs that the data foundation is weak. Without strong infrastructure, AI becomes harder to operationalized. It can still be demonstrated in isolated environments, but not scaled with confidence.
From Martech Fragmentation to AI Marketing Data Infrastructure
The traditional marketing stack was not built for AI
Most marketing enviroments did not start with a clean architectural blueprint. They evolved over time. One platform was chosen for CRM. Another for web analytics. Another for advertising. Another for mobile engagement. Data pipelines were added later. Reporting layers came later still. Each tool solved a real business problem, but together they often created a fragmented ecosystem.
That fragmentation was manageable when marketing was focused mainly on campaigns, channels, and performance reporting. It becomes more problematic when AI is expected to understand customer behavior across the full lifecycle and act on it in near real time.
A customer mayh browse anonymusly on a website, respond to paid media, log in through a mobile app, receive an email, interact with customer service, and later convert through another touchpoint. If those signals remain disconnected, AI cannot interpret the journey properly.
Fragmentation creates blind spots and delays
Fragmented martech creates practical business problems.
Different systems may hold different versions of the customer. Product taxonomies may not match. Event names may vary. Data may refresh at different speeds. Consent and preference status may not travel reliably between platforms. The result is an operating model where teams are often working from partial truth.
This affects more than reporting accuracy. It affects personalization, suppression logic, attribution, eligibility decisions, and journey continuity. It also slows teams down. Every AI use case becomes a custom integration exercise rather than a repeatable capability.
What AI marketing data infrastructure should enable
A strong AI marketing data infrastructure should support several business outcomes at once.
It should help create a more unified view of the customer, even if source systems remain distributed. It should make data available for both analytics and activation. It should process important signals at the right speed for the use case. It should support AI-ready datasets rather than only raw data storage. And it should embed governance, consent, and traceability so that AI can scale responsibly.
In other words, the goal is not to centralize everything for its own sake. The goal is to make the data environment usable, trustworthy, and fit for intelligent marketing.
CDP vs Data Warehouse: Understanding Their Roles in the Modern Marketing Stack
What a CDP is designed to do
A Customer Data Platform is typically designed to help marketers unify customer-related data for activation. In many cases, its strength lies in building usable customer profiles, enabling audience creation, and making it easier to push those audiences into execution channels.
This makes CDPs attractive to marketing teams because they can shorten the path from data to action. A marketer may be able to define segments, trigger journeys, or support profile-based orchestration without relying on engineering teams for every change.
CDPs are often especially useful when the business needs better audience portability, more consistent profile activation, and improved cross-channel orchestration.

What a data warehouse is designed to do
A data warehouse plays a different role. It is usually the environment for scalable storage, data integration, analytics, and historical analysis across multiple business domains. It often serves data engineers, analysts, BI teams, and data scientists more directly than camapgin teams.
A warehouse is valuable because it can consolidate data from many systems, support transformation logic, maintain broader historical depth, and enable complex analysis. It is also often the more flexible environment for feature engineering, model inputs, and enterprise-level governance.
For AI, this matters because many predictiver and analytical use cases need more than customer profiles. They need historical data, cross-functional context, and governed access to multiple data domains.
Why this is rarely a binary choice
The CDP-vesus-warehouse debate is often framed too simply. In practice, many organizations need both capabilities,m even if they are not delivered through two separate products.
A CDP may help create marketer-friendly activation. A warehouse may support enterprise-grade data integration, analysis, and AI feature development. One layer may be stronger at action, the other at depth. The right design depends on the role each plays in the broader architecture.
For example, an organization may use a warehouse as the foundational source for customer, transaction, and behaviopral data, then feed curated profiles into a CDP for activation. Another may use a CDP for profile unification and orchestration while relying on the warehouse for advanced analytics and model training. A third may pursue a composable approach where activation capabilities sit directly on top of warehouse-based data products.
How marketers should think about the right answer
The key is not to ask which platform category is better in general. The key is to ask what the business needs.
If the main challenge is marketer access to usable profiles and audience activation, a CDP may be highly valuable. If the priority is analytical scale, historical depth, and AI model support, the warehouse may be the stronger foundation. If both needs exist, the architecture should reflect both.
That is why AI marketing data infrastructure should be approached as a design question, not a product label. The architecture should follow the use cases, internal capabilities, governance requirements, and activation needs of the organization.
Identity Resolution: The Critical Link Between CDustomer Data and AI Relevance
What identity resolution means in practice
Identity resolution is the process of determining when multiple identifiers or interactions belong to the same person. In a modern customer journey, this is rarely straightforward.
A single individual may browse anonymously on the web, then later log in through an app, open an email on another device, interact with a contact center, and complete a transaction elsewhere. Each interaction may generate a different identifier. Unless these signals can be connected, the customer remains fragmented inside the data environment.
Why fragmented identity weakens AI outcomes
Identify problems are often easy to ignore at first because data sitll appears to be flowing. But the business. impact can be significant.
A recommendation engine may not see the full behavioral history. A personalization layer may mistake a returning customer for a new visitor. Frequency controls may fail. Marketing teams may over-message or under-message because they do not recognize the same person across channels. Attribution models may understate or overstate the role of certain touchpoints.
AI is highly sensitive to this issue because relevance depends on context. The more complete and connected the customer view, the more credible the output becomes.
McKinsey’s personalization research reinforces the commercial side of this challenge. It found that 71% of consumers expect personalized interactions and 76% get frustrated when this does not happen. Meeting those expectations requires more than creative relevance. It requires conected customer data across touchpoints (Source: McKinsey).
Deterministic and probabilistic identity resolution
There are different ways to approach identity resolution.
Deterministic matching uses known identifiers such as customer IDs, login credentials, email addresses or account numbers. It is generally more reliable because it is based on explicit links. Probablistic matching uses inferred patterns such as device behavior, location, or browsiing similarties to estimate likely matches. this can extend coverage, but it introduces lower certaintly and often greater governance complexity.
For many marketing organizations, the best approach is not simply to maximize matches, but to create an appropriate balance between usefulness, confidence, privacy, and explainability.
What strong identity resolution enables
Identity resolution is not just a technical housekeeping exercise. It improves real marketing outcomes.
It supports better segmentatin because audience are based o more complete profiles. It improves personalization because current and historical signals can be interpreted together. It strengthens measurement because conversions can be linked more credibly across channels. It improves customer experience because the business is responding to a person, not to disconnected sessions.
Without it, AI operates on fragments. With it, AI has a better chance of operating on context.
Real-Time Data Pipelines: Why Freshness and Speed Matter
Why batch processing is often not enough
Many organizations sitll move marketing data in batches. For some use cases, that remains perfectly acceptable. Daily reporting, trend analysis, and some predictive modeling do not require instant updates.
But many AI-driven marketing scenarios are time-sensitive. If a customer abandons a journey, shows buying intent, becomes eligible for an offer, or encounters friction, delayed data reduces the value of the responses. A trigger that arives tomorrow may be technically conrrect but commercially late.
This is why a stronger data foundation for AI-driven marketing often includes faster, more responsive data movement.
What real-time pipelines actually do
Real-time pipelines capture, process, enrich, and distribute customer signals quicly enough to support action while the context still matters. That may involve event collection, stream processing, data transformation, and routing to analytics or activation systems.
The business value is not the pipeline itself. The value is what timely data makes possible. It allows an organization to react while intent is current, suppress irrelevant messages after conversion, or tailor journeys based on recent signals.
Where real-time creates the most value
Real-time or near-real-time infrastructure is especially helpful when timing directly influences customer experience or conversion performance.
Common examples include application abandonment, in-session personalization, eligibility updates, service failure recovery, product recommendations, and next-best-action logic. In each of these cases, stale data weakens relevance.
Why not every use case needs true real time
One of the biggest mistakes organizations make is assuming faster is always better.
Real-time infrastructure brings costs and complexity. Not every marketing use case needs it. Some decisions can be made hourly, daily, or even weekly without losing much value. The smarter approach is to design the speed of the data pipeline around the business requirement.
A strong marketing data architecture for AI is therefore not about maximizing speed everwhere. It is about matching freshness to customer and commercial value.
AI-Ready Datasets: What Marketin Data Must Look Like for AI to Work
Raw data is not the same as AI-ready data
Many organizations assume they are ready for AI because they have large amounts of data. But raw data alone is not enough.
AI-ready datasets must be usable, not merely available. They need consistent definitions, reliable quality, appropriate structure, and enough context to support the intended use case. A large pool of event logs with unclear naming, missing fields, and uneven freshness does not create readiness. It creates noise.
The characteristics of AI-ready datasets
AI-ready datasets usually have several common traits. They are accurate enough to support trust. They are unified enough to reflect a menigful customer or business context. They are timely enough for the decisions they support. They are structured enough to be modeled or activated. And they are governed enough to be used responsibly.
IBM defines data quality broadly around accuracy, completeness, validity, consistency, uniqueness, timeliness, and fitness for purpose. That definition is particularly relevant for AI because marketing data does not need to be perfect in the abstractl it needs to be fit for the use case. (Source: IBM).
Why taxonomy, schema, and metadata matter
Data disciplne may sound unglamorous, but it is one of the most important enablers of scalable AI.
Consistent taxonomy helps ensure that products, content, campaigns, and customer interactions are classified in usable ways. Schema discipline ensures envents and attributes are captured consistently across systems. Metadata helps teams understand what a dataset contains, how it was built, how often it rereshes, and where it can be used.
Without this discipline, AI use cases become highly manual. Teams spend too much time cleaning, interpreting, and reconciling data instead of generating value from it.
Build datasets around use cases, not just avilability
One of the strongest weays to improve readiness is to design datasets around decisions.
A churn model may need behavioral decline indicators, service signals, tensure, and product usage. A next-best-offer model may need transaction history, product eligbility, and response patterns. A content recommendation engine may need taxonomy, engagement patterns, and contextual behavior. A generative AI assistant may need access to approved content, structured knowledge, and rules for what can and cannot be surfaced.
In each case, the right question is not “what data do we have?” but “what data does this decision require?”.
That mindset helps create a more effective AI marketing data infrastructure because the architecture becomes aligned to real business use.
Governance and Compliance: The Non-Negotiable Layer of AI Readiness
Why governance is no longer optional
As AI becomes more embedded in marketing decisions, governance become more important, not less.
The reason is simple. AI can scale output quickly. If data is wrong, outdated, non-compliant, or used outside the intened purpose, those risks can also scale quickly. Governance is what helps an organization maintain control, consistency, and trust.
The building blocks of strong governance
Effective governance starts with ownership. Someone needs to be accountable for the definition, quality, and appropriate use of key datasets. It also requires stewardship, which means the operational discipline to maintain data quality and resolve issues over time.
Access management is another critical layer. Not every team, user, or system should have unrestricted access to every type of data. Clear access rules help reduce both risk and confusion.
Consent and preference management are equally important. Customer permissions must be captured clearly and respected consistently across activation environments. If those signals are weak or disconnected, even technically sophisticated AI use cases become difficult to defend.
Auditability also matters. Teams need to understand where data came from, how it was transformed, and how it influenced outputs. This is essential for both compliance and trust.
Good governance enables scale
Governance is often misunderstood as friction. In reality, it is one of the conditions that makes scale possible.
When governance is weak, AI projects face delays, legal concerns, stakeholder resistance, and low trust. When governance is strong, teams can move faster because they know the boundaries, the ownership model, and usage rules.
For marketing leaders, this is a crucial shift in thinking. Governance is not separate from growth. It is part of the operating model that allows growth to happen responsibly.
Common Failure Patterns That Undermine AI Marketing Initiatives
Mistaking tools for readiness
A new AI platform may offer powerful functionality, but it cannot fix fragmented data by itself. Organizations often overestimate what a tool can solve and underestimate how much foundational work is still required.
Overlooking semantics and data quality
Many marketing teams focus on data access but pay too little attention to data meaning. If event names, business definitions, or product taxonomy differs across systems, AI will struggle to operate consistently.
Chasing real time without clear value
Real-time infrastructure is useful when timing matters. But when it is pursued without clear use-case prioritization, it can introduce cost and complexity without enough return.
Treating governance as a final-stage review
If governance is brought in too late, teams often discover constraints after architecture decisions have alaresdy been made. That leads to delay, redesign, or reduced value.
Building isolated fixes instead of durable capability
Point solutions can solve immediate problems, but too many isolated fixes often create new fragmentation. Sustainable progress comes from strengthening shared data foundations, not just patching individual use cases.
A Practical Framework for Building AI Marketing Data Infrastructure
Step 1: Start with the use cases that matter most
Not every AI opportunity deserves equal priority. Begin with use cases that have clear business value and realistic operational requirements. This could be personalization, retention, lead prioritization, audience intelligence, or journey optimization.

Step 2: Map the data requirements clearly
For each use case, identity the needed signals, attributes, systems, and freshness requirements. Clarify what profile data, event data, product information, transaction data, and consent signals are necessary.
Step 3: Assess current-state gaps honestly
Review the current environment against those requirements. Where is identity weak? Where is freshness insufficient? Where are definitions inconsistent? Where is governance unclear? This step often reveals that the biggest blockers are opertional rather than technological.
Step 4: Define architecture roles
Decide what each layer should do. What belongs in the warehouse? What belongs in the CDP or activation layer? Where should identity resolution occur? How will AI-ready datasets be created and maintained? Clarity at this stage prevent duplication and confusion.
Step 5: Build governance into execution
Governance should appear in working processes, not just policy documents. It should influence data definitions, access control, release planning, and usage reviews.
Step 6: Scale in phases
The strongest path is usually incremental. Start with high-value use cases, strengthen the data layer beneth them, prove value, and expand from there. This creates momentum while reducing risk.
What Marketing Leaders Should Ask Before Investing in AI
Do weh have a trustworthy and unified customer view?
If customer records remain fragmented, AI outputs will be less credible.
Can our data move at the speed the use case requires?
Some decisions need real-time context. Others do not. The architecture should reflect that distinction.
Are our datasets built for AI, not just reporting?
Reporting data is not always fit for modeling, personalization, or orchestration.
Is governance strong enough to support trust and scale?
Without clear ownership, usage rules, and consent logic, AI becomes harder to scale responsibly.
Are we building capability or adding another disconnected tools?
This question often separates durable transformation from short-lived experimentation.
Concolsion: AI Marketing Success Starts with Data Foundations
AI has created a new level of ambition in marketing. It promises better relevance, greate efficiency, smarter decisioning, and more adaptive customer experiences. But those outcomes do not come from models alone. They come from the enviroment that supports them.
That is why AI marketing data infrastructure matters so much. It helps determine whether customer data can be connected, whether signals can move at the right speed, whether datasets are usable for AI, and whether governance is strong enough to support trust.
For marketing professionals, the lesson is clear. AI is not only a technology choice. It is also a data and operating model challenge. The organizations that build strong foundations will be far better positioned to turn AI into sustained business value. The ones that do not will continue to run into the same barrier: promising AI ideas built on weak data reality.
In the end, successful AI-driven marketing starts long before the model runs. It starts with the foundation beneath it.
Explore more practical insights on AI, MarTech, digital strategy, and modern marketing infrastructure at AsiaTechBuzz.com. If you found this article useful, you may also enjoy our other in-depth pieces designed for marketing leaders and digital professionals navigating today’s fast-changing landscape.
Frequently Asked Questions (FAQs)
-
What is AI marketing data infrastructure?
AI marketing data infrastructure refers to the architecture, systems, pipelines, and governance needed to support AI-driven marketing use cases. It typically includes customer data platforms, data warehouses, identity resolution, real-time data movement, AI-ready datasets, and compliance controls.
-
Do marketers need both a CDP and a data warehouse?
Not always, but many organizations benefit from using both in complementary ways. A CDP often supports activation and profile-based orchestration, while a data warehouse supports analytics, history, transformation, and model development.
-
Why is identity resolution important in AI-driven marketing?
Identity resolution connects interactions across channels, devices, and systems. Without it, AI works from fragmented customer views, which weakens personalization, measurement, and relevance.
-
Do all AI marketing use cases need real-time data?
No. Some use cases are time-sensitive and benefit strongly from real-time or near-real-time data. Others perform well with batch updates. The right design depends on how much timing affects the business outcome.
-
What makes a dataset AI-ready?
An AI-ready dataset is accurate, consistent, structured, timely, context-rich, and governed for appropriate use. It should be fit for a specific AI use case, not simply available as raw data.
-
Why are governance and compliance essential in AI marketing?
They help ensure that data is used responsibly, consistently, and within approved boundaries. Strong governance improves trust, reduces risk, and makes it easier to scale AI initiatives confidently.








